Home
The Hb-graph datahedron framework
- Details
- Written by: Super User
- Category: Category (en-gb)
- Hits: 9702
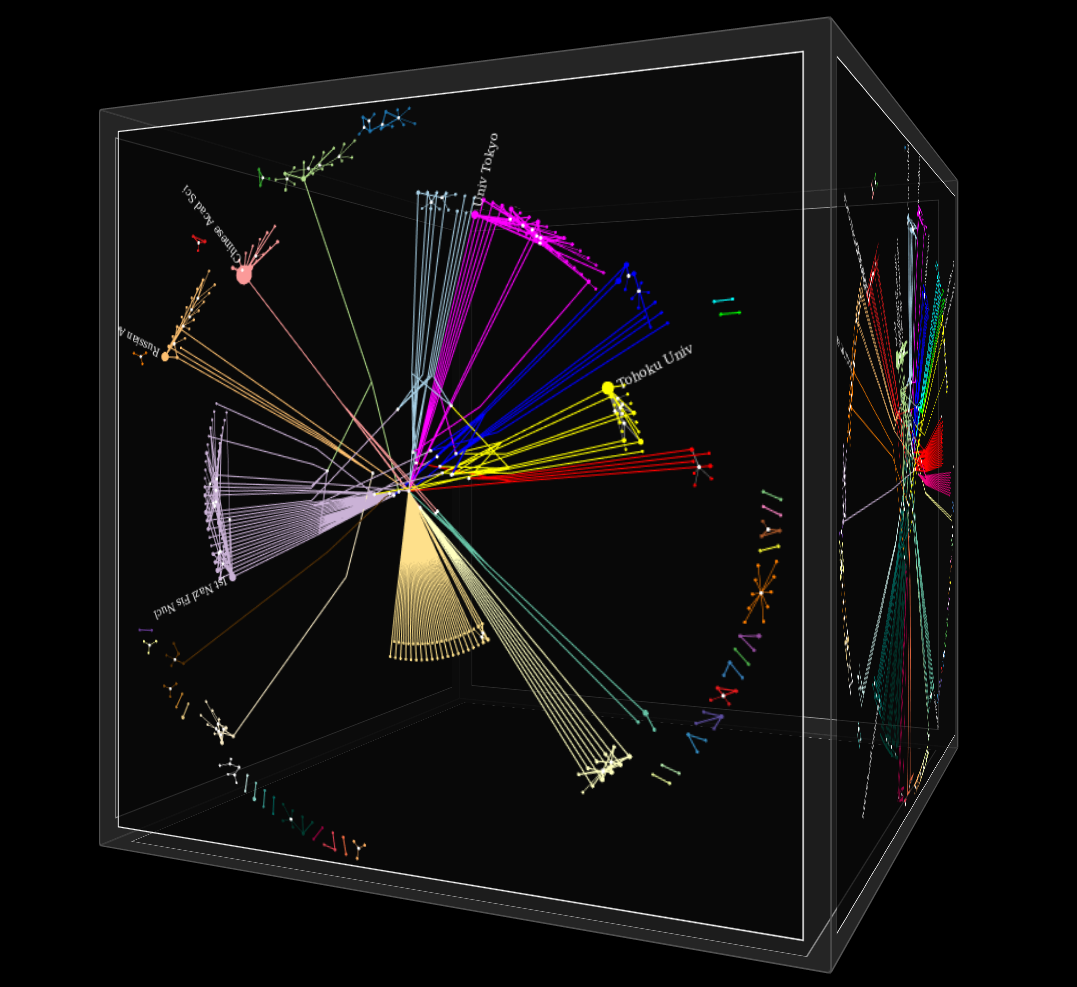
The Hb-graph datahedron framework allows to have an enriched browsing experience of an information space. In traditional verbatim browsers the presentation of query results is linear, either depending on a measure of similarity between the query and the results, typically the binary cosine similarity measure, or depending on more blinded criteria, such as paid places in the ranking.
When performing a query on a textual database, the search is often performed on the title, the abstract and more seldom on the content itself. Textual databases are constituted of elements that have to be seen as physical references. The metadata attached to those documents allow to build co-occurence networks when the reference is chosen. These co-occurence networks can be either heterogeneous, mixing different types of metadata (for instance keywords, authors, organisations, countries, ...) but if we want to have a deep insight into the data we can process them separately: in this case, we will have homogeneous co-occurence networks, that are linked by the physical references, that can be used to switch between the different facets of the information space.
Co-occurences can potentially allow redundancy and mathematically the structure that is adapted is the multisets. Multisets are constituted of a set, called universe, and a multiplicity function on this universe. If the range of the multiplicity function is a subset of the nonnegative integer, we call them natural multisets.
Hypergraphs are families of subsets of a vertex set; the elements of the families are called the hyperedges. Hb-graphs are families of multisets of same universe, called the vertex set. The element of the families are called the hb-edges. Hb-graphs have been invented by ourselves to allow redundancy.
In fact they are used in many domains, but not properly formalised; it includes bags of words, bags of visual words, hyperedge-based vertex weighted hypergraphs. This last designation is misleading, as hyperedges are still sets, and the operations on sets are limited compared to the ones on multisets.
Hypergraphs and hb-graphs are two separate mathematical categories and the move from one to the other is not uniquely a conceptual move.
We first designed a hypergraph framework that we adapted to support hb-graphs.
In practice the Hb-graph datahedron framework is very versatile: it can be used in very different situations where you need to visually query a dataset. It can be enriched with different contextual contents. We highlight it in the following video.
What is my research about?
- Details
- Written by: Super User
- Category: Category (en-gb)
- Hits: 12164
I am currently working on Hypergraph modeling and Visualisation of Co-occurence Networks.
The aim is to gain insights into textual datasets.
Co-occurences are n-adic relationships and are well modeled by hb-graphs, an extension of hypergraphs, that I introduced.
Hb-graphs are families of sub-multisets of a vertex set. A multiset allows the repetition of elements; they are also called bags or msets.
Simplifying the approach one can retrieve hypergraphs, which are families of subsets of vertices.
To visualise different facets of an information space, we built a 2.5D layout that allows to switch between the different facets through the chosen reference and to show co-occurences built vs this reference inside the different facets.